协调器
首先我们需要知道:
DOM 引擎、JS 引擎 相互独立,但又工作在同一线程(主线程) JS 代码调用 DOM API 必须 挂起 JS 引擎、转换传入参数数据、激活 DOM 引擎,DOM 重绘后再转换可能有的返回值,最后激活 JS 引擎并继续执行若有频繁的 DOM API 调用,且浏览器厂商不做“批量处理”优化, 引擎间切换的单位代价将迅速积累若其中有强制重绘的 DOM API 调用,重新计算布局、重新绘制图像会引起更大的性能消耗。
其次是 VDOM 和真实 DOM 的区别和优化:
- 虚拟 DOM 不会立马进行排版与重绘操作
- 虚拟 DOM 进行频繁修改,然后一次性比较并修改真实 DOM 中需要改的部分,最后在真实 DOM 中进行排版与重绘,减少过多DOM节点排版与重绘损耗
- 虚拟 DOM 有效降低大面积真实 DOM 的重绘与排版,因为最终与真实 DOM 比较差异,可以只渲染局部
Diff 算法#
在 beginWork 环节中调用reconcileChildren 时。
- 对于
mount的组件,他会创建新的子Fiber节点 - 对于
update的组件,他会将当前组件与该组件在上次更新时对应的Fiber节点比较(也就是俗称的Diff算法),将比较的结果生成新Fiber节点。
本质:比较当前的
React Element和current Fiber生成workInProgress Fiber
Diff原则#
只对同层的子节点进行比较,不进行跨级节点比较
Tree diff两颗树只会对同一层级的节点进行比较,不同层级的就算说相同节点的移动也会销毁重新创建component diff如果不是同一类型下的组件,则将该组件判断为dirty component,从而替换整个组件下的所有子节点element diff处于同一层级的节点,拥有以下三种操作插入、移动、删除,同时如果某些节点只是在同级发生移位。允许开发者对同一层级的同组子节点,添加唯一key进行区分,提高性能优化。
Tree Diff#
两棵树只会对同一层次的节点进行比较
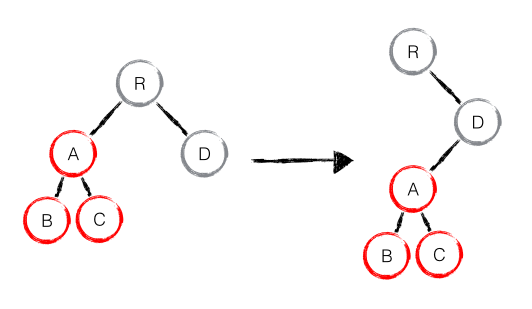
create A -> create B -> create C -> delete A
Component diff#
当 component D 改变为 component G 时,即使这两个 component 结构相似,一旦 React 判断 D 和 G 是不同类型的组件,就不会比较二者的结构,而是直接删除 component D,重新创建 component G 以及其子节点。
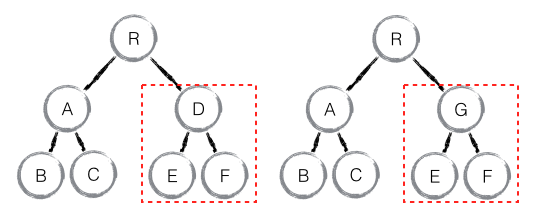
Element diff#
- 当节点处于同一层级时,diff 提供了 3 种节点操作:插入、移动和删除。
- 对于同一层的同组子节点添加唯一 key 进行区分。
新老集合进行 diff 差异化对比,通过 key 发现新老集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将老集合中节点的位置进行移动,更新为新集合中节点的位置,此时 React 给出的 diff 结果为:B、D 不做任何操作,A、C 进行移动操作,即可。
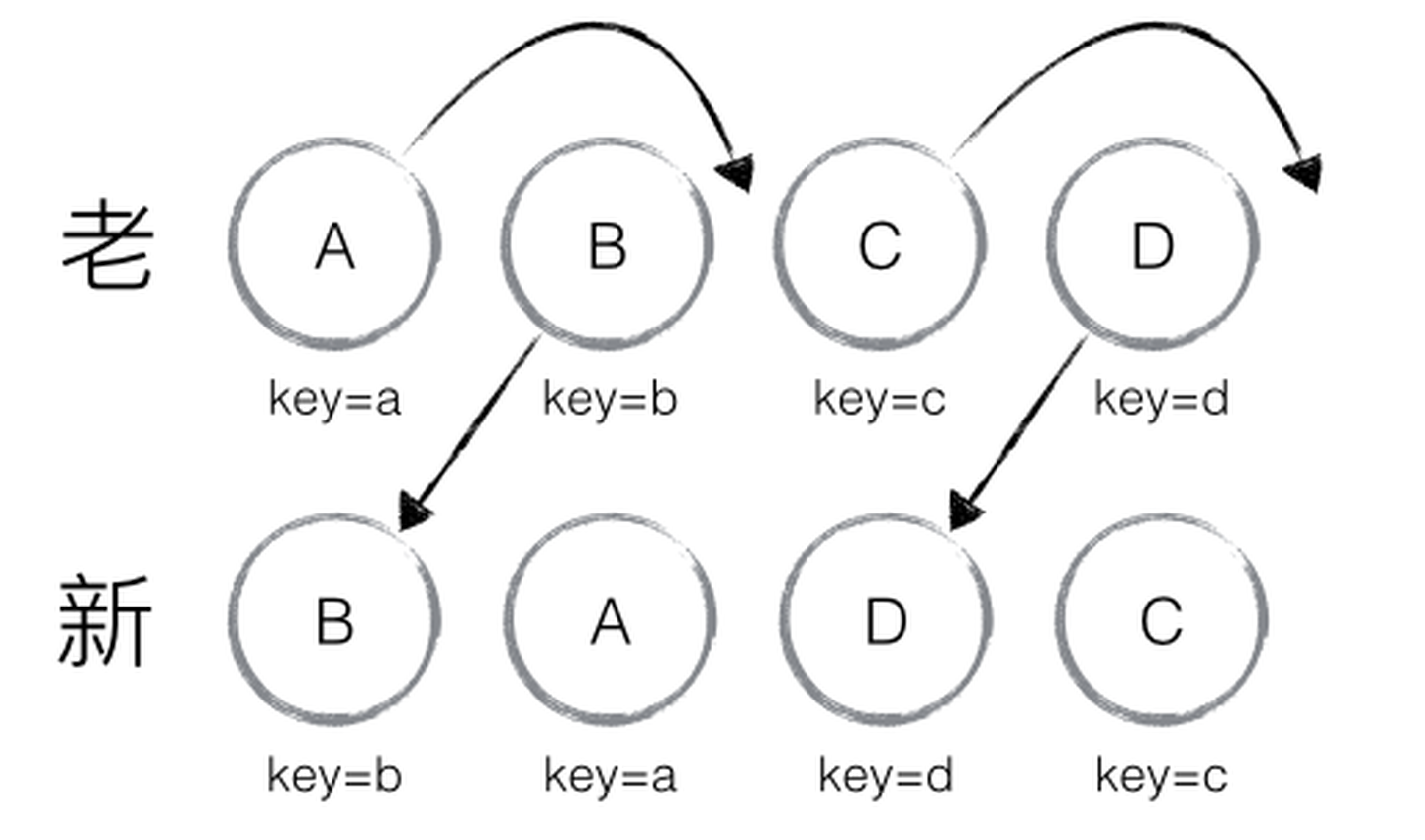
React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key tag来暗示哪些子元素在不同的渲染下能保持稳定。
同级 子树一样 父级不一样 重新生成 key tag 不同顺序 复用
什么是节点的更新呢?对于DOM节点来说,在前后的节点类型(tag)和key都相同的情况下,节点的属性发生了变化,是节点更新。若前后的节点tag或者key不相同,Diff算法会认为新节点和旧节点毫无关系。
Diff算法通过key和tag来对节点进行取舍,可直接将复杂的比对拦截掉,然后降级成节点的移动和增删这样比较简单的操作。对oldFiber和新的ReactElement节点的比对,将会生成新的fiber节点,同时标记上effectTag,这些fiber会被连到workInProgress树中,作为新的WIP节点。树的结构因此被一点点地确定,而新的workInProgress节点也基本定型。这意味着,在diff过后,workInProgress节点的beginWork节点就完成了。接下来会进入completeWork阶段。
协调算法#
无论是应用程序首次渲染还是更新渲染,在解析工作单元的时候 React 均需要执行「协调」算法以获取下一个 Fiber 结点
什么是「协调」?
应用程序执行到 render 阶段构建 workInProgress 树的过程中,每一次工作循环的目的 -> 获取下一个 Fiber 结点的工作都是经过「协调」处理 React 元素来完成。需要注意的是,工作循环的主要任务就是处理当前 Fiber 结点然后返回下一个 Fiber 结点,在这个过程中也会完成结点 diff 处理。
协调的前置工作 — 对不同类型的 Fiber 结点分别解析以获得其子元素
这个逻辑是开始工作单元解析时,在 beginWork函数中根据当前 Fiber 结点的类型分别调用各自的解析函数
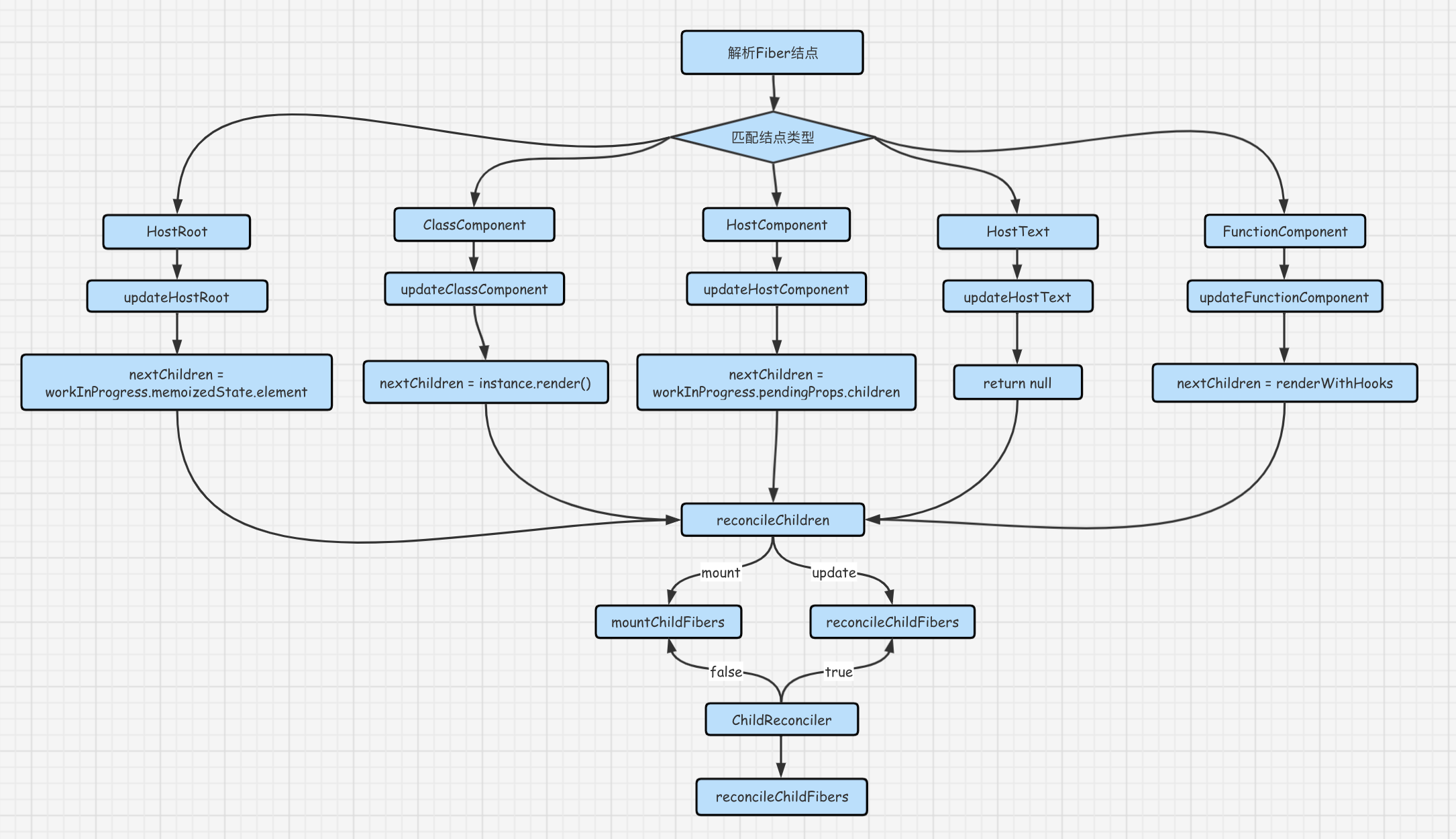
这个过程中首先获取当前 Fiber 结点的子元素,然后将子元素传入 reconcileChildren 函数获取下一个 Fiber 结点
在解析工作单元时,React 需要获得当前 Fiber 结点的子元素并传入到 reconcileChildren 函数中,reconcileChildren函数根据传入的元素返回下一个 Fiber 结点
如果将获取子元素作为整个「协调」算法执行 的前置工作,那么获取下一个 Fiber 结点则是「协调」算法执行的最终目标
协调的最终目标 — 获得下一个 Fiber 结点
reconcileChildren 函数实际上调用的是 reconcileChildFibers 函数,该函数是协调元素的入口函数,函数内部会根据传入的元素类型分别调用对应的处理函数,比如 reconcileSingleElement()、reconcileSinglePortal()、reconcileSinglePortal()分别用于 协调 单个element、 portal 和 text 数据类型的元素并返回新的 Fiber 结点
- 协调单个
element类型的元素
协调过程中坚持的原则就是能复用尽量复用,协调单个元素的主要依据就是先判断结点的 key 是否发生变化,如果没变则选择复用当前的 Fiber 结点并返回,否则创建新的的结点并返回。这里需要注意的是,复用结点并不代表不改变旧的结点,React 会将 element.props 更新到复用的结点中。
- 协调单个
text类型的元素
基本原理同调和单个 element 类型的元素
- 协调
array类型的元素
协调 array 类型的元素的逻辑要比协调单个 element 和 text 类型的结点复杂一些, reconcileChildrenArray 函数用于协调数组的结点
主要有三种情况
- 应用程序首次渲染时,这时
oldFiber为null,React需要为数组中的每一个元素创建一个 Fiber 结点,并将这些结点通过sibling链接起来 - 应用程序更新渲染时,新的元素数组的长度没有发生变化或者长度增加,这时
React将链表中的Fiber结点与新的数组中的每一个元素按照协调单个元素的逻辑进行处理 - 应用程序更新渲染时,新的元素数组的长度相对于旧的
Fiber链表长度变小。这时React依然将链表中的Fiber结点与新的数组中的每一个元素按照协调单个元素的逻辑进行处理,但是数组元素的值却发生了变化。当新的element元素数组的长度相对于旧的Fiber链表长度变小,说明应用程序删除了某元素。此时React会找到元素之前在数组中的索引位置,然后将其值设置为false,然后将其对应的 Fiber 结点的effectTag标记为Deletion
对整个「协调」算法总结一下
协调的对象是 React 元素,得到的是下一个 Fiber 结点。
我们常说的 React 中的
diff算法是「协调」逻辑的一部分,被diff的双方分别是(新)元素和(已有)Fiber结点。执行「协调」的过程对于单个元素和数组元素分别执行不同的方法进行处理
应用程序首次渲染时一般不涉及到
diff过程,因为所有的元素均会转换为要插入的 Fiber 结点。应用程序更新渲染时通过进行(新)元素和(已有)Fiber 结点的 diff 处理,对结点标记对应的
effectTag
在完成工作单元时 React 将所有标记了 effectTag 的结点收集起来,形成了 Effect List。下一节将会以具体实例说 明更新渲染时的 Effect List 到底是什么样的。